LLM Agentic Framework for ABSA
First agentic framework for Aspect-Based Sentiment Analysis using Generator-Evaluator LLM-as-judge workflow. Published at EACL 2026.
- Python
- Hugging Face
- Ollama
- ReAct Agents
- Tool Calling
- LLM Evaluation
- Prompt Engineering
- NLP
Overview
Aspect-Based Sentiment Analysis (ABSA) requires fine-grained identification of sentiment toward specific aspects in text — but labeled training data is scarce and expensive to produce. This research introduces the first agentic data augmentation framework for ABSA, using a Generator-Evaluator architecture built on a ReAct-style agent framework. A generator agent extracts style policies and produces candidate sentences, while an evaluator agent verifies label consistency before accepting them into the synthetic dataset. This structured pipeline produces significantly cleaner data than naive prompting — the same model, same prompts, but with explicit verification steps making all the difference.
Architecture
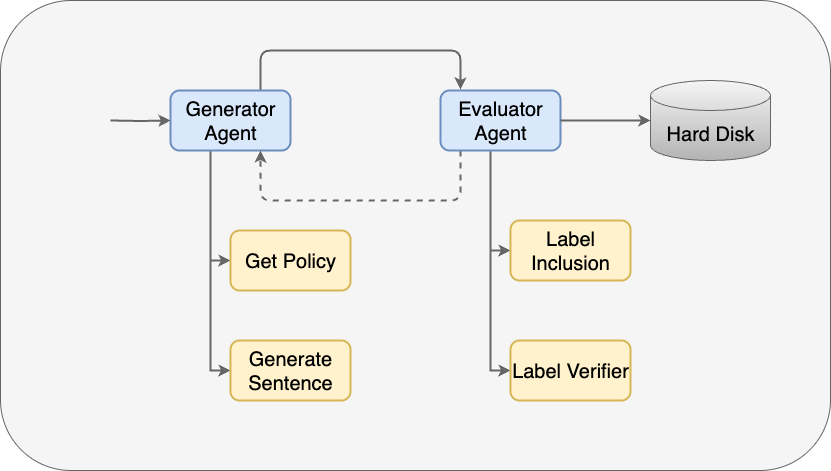
Results
- Agentic augmentation achieved 78.17% label consistency in ATE vs 43.89% for raw prompting
- T5-Base with agentic mixed data matched or surpassed the heavily pretrained Tk-Instruct baseline
- Consistent F1 improvements across ATE and ATSC subtasks on all 4 SemEval datasets
- Evaluated across Laptop14, Rest14, Rest15, Rest16 benchmarks using InstructABSA framework
- Synthetic-only training gap confirmed — agentic data most effective when mixed 1:1 with real data